今天是2023年1月1日元旦!祝看到这篇文章的所有人新年快乐!
我们都知道,在大部分OOP语言里,一个类中的方法可以被另一个类重写,例如:
public class Base
{
public virtual void M()
{
Console.WriteLine("I am Base");
}
}
public class Derived : Base
{
public override void M()
{
Console.WriteLine("I am Derived");
}
}
在上面这个例子里,子类Derived重写了基类Base的方法M,因此调用Derived.M()和Base.M()时,输出结果是不一样的。考虑下面这段代码
Base b1 = new Derived();
Base b2 = new Base();
b1.M();
b2.M();
在这段代码中,b1和b2的类型都是Base,但是显然他们的行为应当不同,因为他们实际上的类型是一个Base一个Derived,这种同一个类型上的同一个函数拥有不同表现的行为被称为多态(有关多态与多态之间的区别详见Rust的设计哲学:Trait与多态)。那么问题来了,编译器在生成代码,或者解释器在执行这段代码的时候,怎么知道b1和b2上对M()的调用应该链接到Base.M()还是Derived.M()呢?
简单来说,每个类型在编译器内都有一个属于自己的描述符(Descriptor),这个描述符包含了这个类型的元数据,在这个描述符中,会有一个叫做虚方法表(Virtual Method Table)的字段,这个字段储存了这个类型的每个方法的实际入口点(实际地址或者虚拟机中表示一个方法入口点的数据结构),比如Derived类型的虚方法表对应M()方法的地址是0x12345678,而Base类型中的虚方法表对应M()方法的地址是0x23456789,通过这种办法,当编译器编译/解释b1.M()和b2.M()时,会先查询b1和b2的类型描述符,接着再去查虚方法表,接着跳转到虚方法表中对应M()方法的位置。在C#的中间语言MSIL里,虚方法调用一般使用指令callvirt表示,而在Java中,则是字节码指令invokevirtual,这两条指令告诉编译器该方法调用是一个虚方法调用,因此需要查虚方法表。相反的,如果一个方法不是虚方法,那么编译器无需查虚方法表就知道该跳转到哪里——因为非虚方法全局只有一个,不存在继承重写的问题,此时的指令将会是calli或call而非callvirt。上文的例子对应的IL就是:
.maxstack 1
.locals init (
[0] class Base b1,
[1] class Base b2
)
IL_0000: nop
IL_0001: newobj instance void Derived::.ctor()
IL_0006: stloc.0
IL_0007: newobj instance void Base::.ctor()
IL_000c: stloc.1
IL_000d: ldloc.0
IL_000e: callvirt instance void Base::M()
IL_0013: nop
IL_0014: ldloc.1
IL_0015: callvirt instance void Base::M()
IL_001a: nop
IL_001b: ret
可以看到位于IL_000e与IL_0015的两个callvirt指令,分别对应b1.M()和b2.M()。
但是现在引入了一个新的问题:从上面介绍的对虚方法调用的过程也可以看出来,虚方法的调用需要好几步的中间步骤,尤其是查找虚方法表这一步,相比起非虚方法来说要麻烦的多,而事实也的确如此,对于虚方法来说,其调用的性能开销往往是非虚方法的好几倍,这样的性能开销,有没有可能避免呢?
答案是肯定的,我们可以注意到,在上面的例子里,我们对b1.M()和b2.M()的调用紧跟在b1和b2的对象创建之后,而在对象创建的时候,b1和b2的具体类型是清晰可见的,因此,在这种情况下,编译器能够通过上下文分析推断出b1是Derived类型而b2是Base类型,在这种时候,编译器就有能力把callvirt instance void Base::M()直接替换成一个对Derived::M()的直接调用,省掉查询虚方法表的开销,这一步优化被称为Devirtualization。
然而,在大部分时间里,这种创建对象并且在同一个方法内调用的情景都是见不到的,更多情况是这样子的:
public void Invoke(Base b)
{
b.M();
}
也即Base被作为一个参数传递进来,此时b的定义和使用不在一个方法里,再去用上下文分析就会变得相当困难,这种情况下,上面提到的Devirtualization手段就会显得非常鸡肋,dotnet/runtime中有关Devirtualization的文档里写到:
However, most of the time the JIT is unable to determine exactness or finalness and so devirtualization fails. Statistics show that currently only around 15% of virtual call sites can be devirtualized. Result are even more pessimistic for interface calls, where success rates are around 5%.
也就是,依赖上下文分析的Devirtualization成功率只有15%,而遇到接口类型的时候,这个概率还会再降低到可怜的5%。
那么有没有可能解决这个问题呢?有,RyuJIT的开发者们选择了另外一种办法:Guarded Devirtualization。既然编译器不能够在编译期简单的通过上下文分析来判断出类型,那么就干脆插一个运行的检查,称为Guard,简而言之,Guarded Devirtualization就是把无法通过上下文分析的callvirt,诸如上面的Invoke方法,变成这样(伪代码):
public void Invoke(Base b)
{
if (b is Derived)
{
// 直接调用
call instance void Derived::M()
}
else
{
// 否则继续用默认的callvirt
callvirt instance void Base::M()
}
}
可以看到,JIT会在运行时把b.M()复制成两份,一份使用calli放在if的then分支里,另一份使用默认的callvirt放在if的else分支里,当类型判断成功,b的类型就是Derived时,就会不走虚方法表直接调用,否则fallback回默认的callvirt行为。
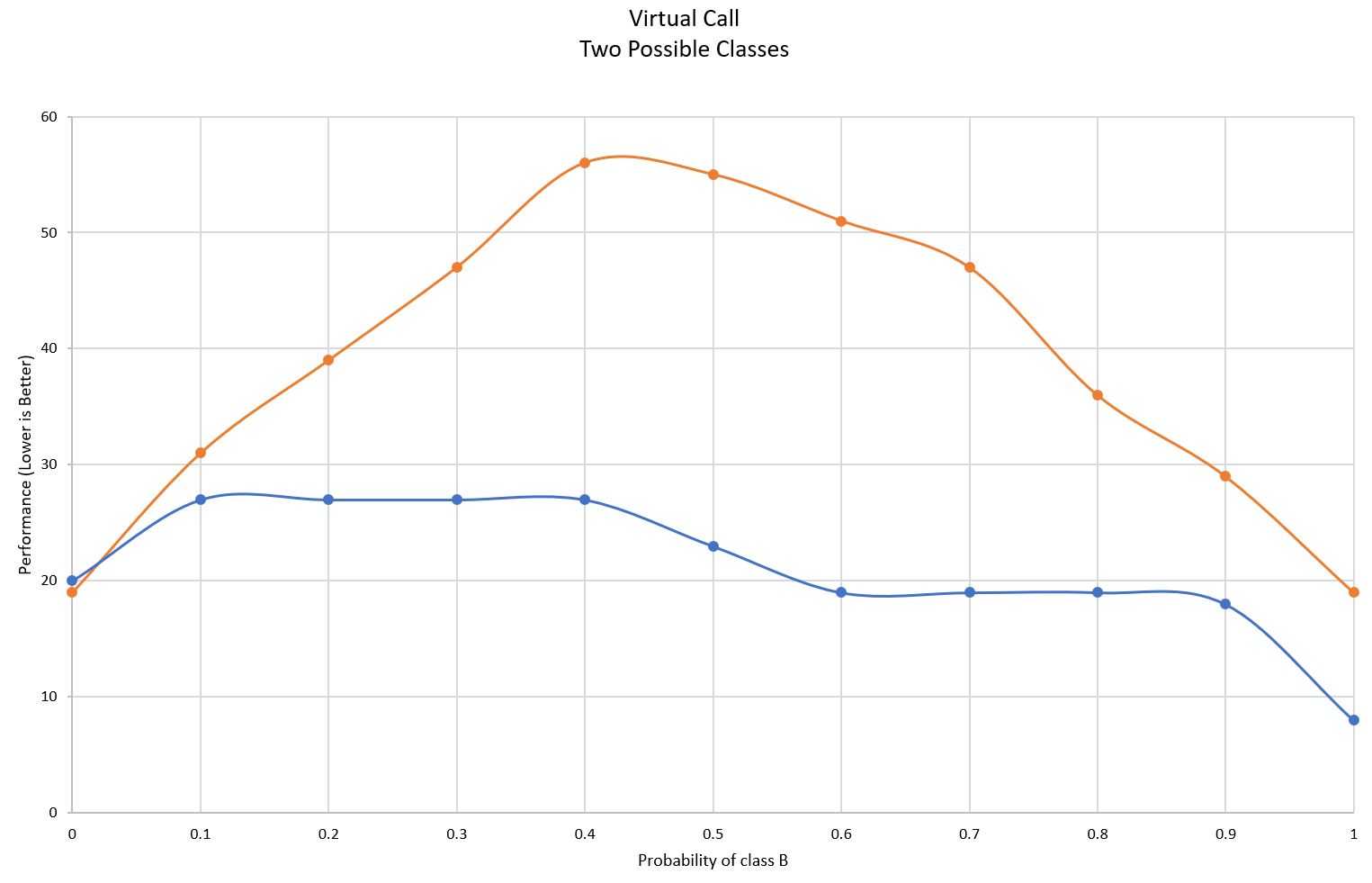
这个做法的聪明之处在于,这个额外插入的if判断和两个分支是可以被现代CPU的分支预测器去预测的,当绝大部分情况下b都是Derived时,分支预测落入then的成功率较高;而当b绝大部分情况下都是Base时,落入else的成功率则较高,同时因为else分支仅限于b是Base类型的情况,因此CPU的间接分支预测器(Indirect Branch Predictor)的预测成功率也会非常高(先预测落入else然后预测跳转到Base::M()的地址);当Base和Derived概率相当的时候,虽然分支预测器和间接分支预测器的预测效果不佳,但是至少有一半的情况下,代码会流入then分支,执行优化后不需要查虚方法表的直接调用,因此性能也不会差到哪里去,实际上,根据dotnet/runtime开发者文档中的统计,使用Guarded Devirtualization后无论任何情况下(Base和Derived的任意比例下)性能都要优于没有使用Guarded Devirtualization的代码(图中蓝线对应使用了Guarded Devirtualization的情况,橙线对应未优化的代码):
除了优化虚方法表开销,提升函数调用的性能以外,Devirtualization还有一个很重要的功能——为后续优化铺路。能看到本文这里的读者大概都知道什么是内联优化(Inlining),也就是把一个函数的函数体,复制到该函数被调用的位置,诸如
public int B()
{
return 33;
}
public void D()
{
Console.WriteLine(B());
}
如果在D()中对B()的调用位置内联B(),代码就会变成
public void D()
{
Console.WriteLine(33);
}
可以看到,对B()的调用被替换成了B()的函数体本身,消除了一次函数调用的开销。内联是相当重要的一个优化,不仅仅因为函数调用是一个很重的开销,更是因为内联之后可以方便后续优化。但是从上面例子也可以看出内联一个很重要的需求:必须要知道调用的到底是哪个函数才能够执行内联,毕竟如果你压根不知道这个函数到底是哪一个,又怎么能选出正确的实现并且复制其函数体呢?这就是在OOP语言中会遇到的问题,例如在上面的例子里,默认情况下Base::M()的调用就是无法被内联的,因为不知道这个M()到底调用的是Derived::M()还是Base::M()。这时候Devirtualization就起到了至关重要的作用:如果可以直接通过上下文分析出b1和b2的类型,那么可以直接内联Derived::M()和Base::M()到b1.M()和b2.M()这两个调用处;即便上下文分析不出,Guarded Devirtualization的then分支中也可以保证b是Derived类型的,因此then分支内部的代码不仅可以变成直接调用省去虚方法开销,更可以进一步直接将已经确定要被调用的函数内联到then分支中,这样,优化后的代码就变成了:
public void Invoke(Base b)
{
if (b is Derived)
{
// 内联的Derived::M()
Console.WriteLine("I am Derived");
}
else
{
// 否则继续用默认的callvirt
callvirt instance void Base::M()
}
}
这样,代码的效率就会更进一步。同时,内联之后会让很多原本的过程间分析(Interprocedural Analysis,一种跨越多个函数边界,一般来说相当耗时的编译器分析技术)变成普通的过程内分析,把分析的范围限制到一个函数内,这样能大大有助于后续优化。
值得注意的是,在Guarded Devirtualization这个优化中,被优化的部分被“复制”了两份,一份是优化路径,一份是回退路径,这种把原代码复制两份的优化和回退策略在编译器优化中也算是相当常见,这种策略的另一个例子就是循环复制(Loop Cloning),就如同它的名字暗示的,这种策略经常被用在循环优化上,将循环体复制两份,一份用作符合优化条件的快路径(Fast Path),一份用作默认未优化的慢路径(Slow Path)。这么做的一个例子是边界检查消除(Bound-Check Elimination),这是一种相当基础和常见的优化,在大部分高级语言中,循环遍历一个数组时,编译器都会在循环条件上插一个边界检查,判断当前的索引是否越界,如果越界就抛出异常,以此避免非法内存访问并且及时提醒开发者。但是,在许多例子中,边界检查是不必要的,比如在如下的例子里:
public void B(int[] arr)
{
for (var i = 0; i < arr.Length; i++)
{
Console.WriteLine(arr[i]);
}
}
在这个例子中,循环条件限制了i小于arr.Length,也就是数组arr的长度,因此索引越界的问题在这里是一定不会发生的。这种情况下,编译器就可以去除掉对arr[i]的边界检查。我们来再看一个例子:
public void B()
{
int[] arr = new int[4];
for (var i = 0; i < arr.Length; i++)
{
Console.WriteLine(arr[i]);
}
}
public void D(int length)
{
int[] arr = new int[4];
for (var i = 0; i < length; i++)
{
Console.WriteLine(arr[i]);
}
}
这个例子中,B函数是不需要边界检查的,而D函数是需要边界检查的,因为的循环条件是一个外部传递进来的参数length,因此,对于带有此类型循环优化的编译器来说,B函数生成的代码应该是不包含边界检查的,如同下文中的汇编代码所示:
Program.B()
L0000: push ebp
L0001: mov ebp, esp
L0003: push edi
L0004: push esi
L0005: mov ecx, 0x721699c
L000a: mov edx, 4
L000f: call 0x068a319c
L0014: mov esi, eax
L0016: xor edi, edi // 设i = 0
// 循环体开始
L0018: mov ecx, [esi+edi*4+8] // 取出arr[i]
L001c: call dword ptr [0x5947768] // 调用Console.WriteLine
L0022: inc edi // i++
L0023: cmp edi, 4 // 将i和4比较
L0026: jl short L0018 // 如果i小于4则跳转回循环开头
// 循环体结束
L0028: pop esi // 清理栈
L0029: pop edi
L002a: pop ebp
L002b: ret
可以看到,在从L0018到L0026的循环体中一共包含了五条指令,而这位五条指令没有一条是涉及边界检查的,另外注意,在L0023行是直接将i和4比较,而不是和arr.Length比较,这是另一项叫做复写传播(Copy Propagation)的优化,也就是将变量的use site替换为他们的值。接下来,我们可以看一下D函数生成的汇编代码:
Program.D(Int32)
L0000: push ebp
L0001: mov ebp, esp
L0003: push edi
L0004: push esi
L0005: push ebx
L0006: mov esi, edx
L0008: mov ecx, 0x721699c
L000d: mov edx, 4
L0012: call 0x068a319c
L0017: mov edi, eax
L0019: xor ebx, ebx // 设i = 0
L001b: test esi, esi
L001d: jle short L004d // 和上一行一起判断如果length = 0就直接返回
L001f: test esi, esi
L0021: jl short L0039 // 和上一行一起判断如果length < 0就跳转到L0039
L0023: cmp esi, 4
L0026: jg short L0039 // 和上一行一起判断如果length > 4就跳转到L0039
// 第一个循环开始(Fast Path)
L0028: mov ecx, [edi+ebx*4+8] // 取出arr[i]
L002c: call dword ptr [0x5947768] // 调用Console.WriteLine
L0032: inc ebx // i++
L0033: cmp ebx, esi // 将i和length比较
L0035: jl short L0028 // 如果小于length则跳转回循环开头
// 第一个循环结束
L0037: jmp short L004d // 如果执行的是第一个循环,循环结束后返回
// 第二个循环开始(Slow Path)
L0039: cmp ebx, 4 // 比较i和4
L003c: jae short L0052 // 边界检查:如果i >= 4则跳转到L0052
L003e: mov ecx, [edi+ebx*4+8] // 取出arr[i]
L0042: call dword ptr [0x5947768] // 调用Console.WriteLine
L0048: inc ebx // i++
L0049: cmp ebx, esi // 将i和length比较
L004b: jl short L0039 // 如果小于length则跳转回循环开头
// 第二个循环结束
L004d: pop ebx // 清理栈
L004e: pop esi
L004f: pop edi
L0050: pop ebp
L0051: ret
L0052: call 0x7218a060 // throw new IndexOutOfRangeException(); 抛出越界异常
L0057: int3
可以看到,在D生成的代码中,存在两个循环,这就是循环复制的功劳:JIT将原函数体内的for循环复制了两份,一份用作快路径,一份用作慢路径。两个循环中,第一个循环被去除了边界检查,第二个循环则带有边界检查,可以看到JIT在函数开头的部分插入了判断length < 0 || length > 4的检查,如果符合就跳转到第二个循环,因为此时length存在越界问题,在第二个循环中,一旦发现i越界(大于等于4就会跳转到L0052抛出异常);否则就执行第一个循环,因为此时length被保证不小于0且不大于4。以上的汇编,如果反编译成C#代码,就是这个样子的,注意被复制的循环体和第二个循环中的边界检查:
public void D(int length)
{
var arr = new int[4];
if (length == 0)
return;
if (length < 0 || length > 4)
{
var i = 0;
do
{
if (i >= 4)
throw new IndexOutOfRangeException();
Console.WriteLine(arr[i]);
i++;
} while (i < length);
}
else
{
var i = 0;
do
{
Console.WriteLine(arr[i]);
i++;
} while (i < length);
}
}
这种对函数体的复制/插入运行时检查的方法,也会应用在诸如Hot-Cold Splitting这样的优化上用于分离一个函数内的Hot Path和Cold Path。今天看到了一个视频,里面有一个非常奇葩的地方,是对比C/C++和Rust的效率,他的对比方法居然是对比生成的汇编代码的长短,颇令我感觉有点哭笑不得,在这篇文章里我们可以看到,汇编代码的多少和代码的性能没有直接关系,很多时候优化过后的代码反而更长。还有类似之前说代码嵌套最好不要超过三层的视频...真希望这样子的视频能够少一点,多一点有价值有意义讲的东西至少是正确的视频。

Comments 3 条评论
我参考
https://unix.stackexchange.com/questions/400650/counting-the-characters-of-each-line-with-wc
https://unix.stackexchange.com/questions/387656/how-to-count-the-times-a-specific-character-appears-in-a-file
扣了丶垃圾bash来找出具有最长的以
空格或tab开头的行的文件:参考
https://unix.stackexchange.com/questions/170043/sort-and-count-number-of-occurrence-of-lines
https://unix.stackexchange.com/questions/177777/drawing-a-histogram-from-a-bash-command-output
的输出ascii art直方图版本(不显示文件名因为across all files,每个
=代表有5行是以第一列值个空格缩进的,不到5行的省略=):提前该视频up主立即对 https://github.com/torvalds/linux 和 https://github.com/chromium/chromium 执行此bash分析
在我的tbm项目中有:
43个空格(10.75层嵌套): https://github.com/n0099/TiebaMonitor/blob/e84a230fa0eb1c1095f6b6aa74b34a29f1f6a69d/crawler/src/Worker/InsertAllPostContentsIntoSonicWorker.cs#L146
40个空格(10层嵌套): https://github.com/n0099/TiebaMonitor/blob/e84a230fa0eb1c1095f6b6aa74b34a29f1f6a69d/be/app/Http/PostsQuery/BaseQuery.php#L175
56个空格(14层嵌套): https://github.com/n0099/TiebaMonitor/blob/e84a230fa0eb1c1095f6b6aa74b34a29f1f6a69d/fe/src/components/Post/ViewList.vue#L112
@n0099 我在那个视频下面就发了自己的反对意见

@dylech30th 建议立即提前
四叶FP头子仏国xx第二大学CS硕士PLT中级高手仏国白左仏皇irol女士以fp思维为抓手,打出一套基于haskell typeclass Just Maybe单子 y组合子的组合拳,赋能现代前端娱乐圈vue壬上壬最爱的template伪html dom结构语法中的