本文中用P_n表示P[1..n],用P[n]表示P中的第n个字符,用P_i\sqsupset P_q代表P_i是P_q的后缀,用P_i\sqsubset P_q代表P_i是P_q的前缀,所有下标从1开始
因为太久不看完全忘记了KMP算法究竟是怎么实现的,看龙书的时候发现上面的题目赫然印着相关内容而我却完全看不懂,遂翻开算法导论大战一个多小时重温了这个各方面复杂度都十分优秀的字符串匹配算法
KMP算法是一种优化过的有限自动机匹配算法,和有限自动机需要花费O(m|\Sigma|)(其中m是模式串的长度)的时间生成状态转移表不同的是,KMP算法通过维护一张更小的表来尝试跳过不可能成功匹配的字符串并以此将"准备阶段"的效率提高的O(m),在扫描阶段,KMP和有限自动机算法拥有相同的线性时间复杂度
KMP算法的核心基于这样的观察,假设匹配串T=bacbababaabcbab,模式串P=ababaca,当我们匹配到某一个位置的时候:
\def\b{\boldsymbol{b}}
\def\c{\boldsymbol{c}}
\begin{array}{ccccccccccccccc}
b&a&c&b&\a&\b&\a&\b&\a&a&b&c&b&a&b& \\
&&&&\a&\b&\a&\b&\a&c&a
\end{array}
此时令P相对于T的偏移量为s,此例中s=4(本文中下标从1开始,遵循CLRS的规范),已匹配长度为q,此例中q=5(ababa),在该情况下我们已经成功匹配了5个字符,但是第6个字符a和c不匹配,KMP的核心思想在于,当我们知道已匹配长度q和已匹配的字符串P_q,就能立即知道某些s一定是无效的,比如在这个例子中,s+1一定是无效的,因为当s+1时,我们有
b&a&c&b&a&b&a&b&a&a&b&c&b&a&b& \\
&&&&&a&b&a&b&a&c&a
\end{array}
b和a显然是不匹配的,但是,如果我们把s向右推进2,就变成了
\def\b{\boldsymbol{b}}
\def\c{\boldsymbol{c}}
\begin{array}{ccccccccccccccc}
b&a&c&b&a&b&\a&\b&\a&a&b&c&b&a&b& \\
&&&&&&\a&\b&\a&b&a&c&a
\end{array}
此时s'=s+1,并且P和T中再次出现了长度k=3匹配,也就是我们通过把s推进2次跳过了五次多余的匹配,直接从P[4]开始,诸如类似k的值会被一个特殊的函数计算出来并储存在表\pi中,比如在上面的情况中就可以直接通过\pi[q]=\pi[5]=3来得到k的值并且把s推进q-k=2次,令s'=s+(q-\pi[q]),我们就可以在一次失败匹配后直接得到下一次匹配的开始下标。
很明显,我们的目的是跳过尽可能长的"无用"字符串,也就是不可能成功匹配的字符串,那么就存在一个这样的问题:
假设P[1..q]和T[s+1..s+q]匹配,找到一个最大的偏移量s',使得对于k\lt q且s'+k=s+q,存在P[1..k]=T[s'+1..s'+k]
(这个描述比较拗口,但是可以结合前三张图示理解)
换言之,就是对在同一下标结束的匹配的字符串,比如上图中的两次匹配,一次q=5一次q=3,都在T[9]处结束,对于T来说,匹配的字符串的末端下标没有变化,我们已经知道P_q\sqsupset T_{s+q}(不言而喻),那么应当找出一个k<q,让P_k\sqsupset T_{s+q}(这里的s+q可以换成s'+k,相当于下标s增加到了s'而匹配的文本串长度p长度减小到了k,在上面的例子中,下标s=4增加到了s'=6,而q=5减小到了k=3,两者互补最终的和依然是9),既然我们的目的是增大"跳过"的数量也就是s'的值,我们又知道s'+k=s+q,在给定s和q的情况下,最大化s'值的方法自然是最小化k的值。而k的最小值自然是0,也就是对于任何k\lt q,都不存在P_k\sqsupset T_{s+q}的情况
最佳情况演示
之前:\def\a{\boldsymbol{a}}
\def\b{\boldsymbol{b}}
\def\c{\boldsymbol{c}}
\begin{array}{ccccccccccccccc}
b&a&c&b&a&b&\a&\b&\b&a&b&c&b&a&b& \\
&&&&&&\a&\b&\b&b&a&c&b
\end{array}之后:
\def\a{\boldsymbol{a}}
\def\b{\boldsymbol{b}}
\def\c{\boldsymbol{c}}
\begin{array}{ccccccccccccccc}
b&a&c&b&a&b&a&b&b&\a&\b&c&b&a&b& \\
&&&&&&&&&\a&\b&b&b&a&c&b
\end{array}s直接从6跳过了q=3变成了s'=9,这种情况下k=0,这种情况的前提是根本不存在一个k\lt q使得P_k\sqsupset T_{s+q},在上面的例子中,只有abb才是abb的后缀,往右挪动P,无论ab还是单a都不是T_{s+q}(或者T_{s'+k}(k=0)的后缀
此时我们需要做出另外一个观察,很明显,P_q\sqsupset T_{s+q},同时P_k\sqsupset T_{s+q}并且|P_k|\lt |P_q|,这蕴含着P_k\sqsupset P_q,而根据上文中的图示可以看出同时P_k\sqsubset P_q。因此,我们的目标就是寻找一个最大的k使得P_k既是P_q的后缀又是P_q的前缀,总结出这一点,我们就可以填充表\pi了
令\pi是\lbrace1,2,3,...,m\rbrace到\lbrace0,1,2,...,m-1\rbrace的函数,有\pi[q]=max\lbrace k\lt q且P_k\sqsupset P_q\rbrace,换言之,就是要求P_k是最长的既是P_q前缀(k\lt q本身就蕴含了P_k\sqsubset P_q)又是P_q真后缀的字符串,同时P_k\neq P_q,即P_q的最长公共前后缀
我们先给出一个计算\pi的函数叫做前缀函数,接着分析该函数的正确性

该函数的核心思想基于这样的观察,考虑一个例子,如字符串abab?,假设我们已经知道了当前的最长公共前后缀是ab,也就是长度为2,那么当?是什么的时候,可以让该字符串的最公共前后缀长度为3?这个答案很明显是c,因为前三个字母aba是确定的,想要让公共前后缀长度为3,则前缀和后缀都必须是aba,因此只需要判断a是否等于?即可。现在设P=ababaa,要计算P_0..P_q中的所有子串的最长公共前后缀,首先设置两个指针k和q,其中令k的初始值是0,q是1,这代表第q_0不存在任何公共前后缀,接下来,我们尝试着模拟迭代,第一次迭代之前,k=0,q=1,令\pi[1]=k=0,代表第一个字符本身没有任何公共前后缀(因为我们要求后缀必须是真后缀,而单个字符的后缀只有它本身,不满足真后缀要求),我们有
\def\b{\boldsymbol{b}}
\def\c{\boldsymbol{c}}
\begin{array}{ccccccc}
0&1&2&3&4&5&6\\
&a&b&a&b&a&a\\
\uparrow_k&&\uparrow_q\\
\pi&0
\end{array}
指针指出了k和q现在的位置,接着我们进入第一次迭代,此时k=0,q=2,我们比较P[k+1]和P[2]是否相等,很显然a\neq b,因此我们让\pi[q]=\pi[2]=k=0,也就是P_2不存在任何公共前后缀,此时进入第二次迭代,进入第二次迭代前有
\def\b{\boldsymbol{b}}
\def\c{\boldsymbol{c}}
\begin{array}{ccccccc}
0&1&2&3&4&5&6\\
&a&b&a&b&a&a\\
\uparrow_k&&&\uparrow_q\\
\pi&0&0
\end{array}
此时再次比较,发现P[k+1]=P[q],此时将k递增1,令\pi[q]=\pi[3]=k=1,代表P_q=P_3有长度为1的最长公共前后缀,代表进入第三次迭代,进入第三次迭代前有
\def\b{\boldsymbol{b}}
\def\c{\boldsymbol{c}}
\begin{array}{ccccccc}
0&1&2&3&4&5&6\\
&a&b&a&b&a&a\\
&\uparrow_k&&&\uparrow_q\\
\pi&0&0&1
\end{array}
依然符合P[k+1]=P[q],于是k再次递增1,\pi[q]=\pi[4]=k=2,继续下去有
\def\b{\boldsymbol{b}}
\def\c{\boldsymbol{c}}
\begin{array}{ccccccc}
0&1&2&3&4&5&6\\
&a&b&a&b&a&a\\
&&\uparrow_k&&&\uparrow_q\\
\pi&0&0&1&2
\end{array}
依然P[k+1]=P[q],递增k,\pi[q]=\pi[5]=k=3
\def\b{\boldsymbol{b}}
\def\c{\boldsymbol{c}}
\begin{array}{ccccccc}
0&1&2&3&4&5&6\\
&a&b&a&b&a&a\\
&&&\uparrow_k&&&\uparrow_q\\
\pi&0&0&1&2&3
\end{array}
好,现在我们发现了一个问题,P[k+1]\neq P[q]了,但是k=3,这时候我们该怎么填\pi[6]呢,简单的直接把k归零肯定是不行的,因为很明显上图中\pi[6]应当等于1,解决办法是这样的:我们把k从当前的位置开始往后倒着推,找出之前的每一个k'使得P_k'\sqsupset P_{q-1},也就是P_{q-1}的所有公共前后缀的集合(为啥不是P_q?因为我们现在正在找的就是P_q的啊),接着看看在这个k'的位置上,P[k'+1]是否会等于P[q],如果存在这么一个k',那么说明此时P_q最长公共前后缀长度就是长度为k'+1的P_{k'+1}。
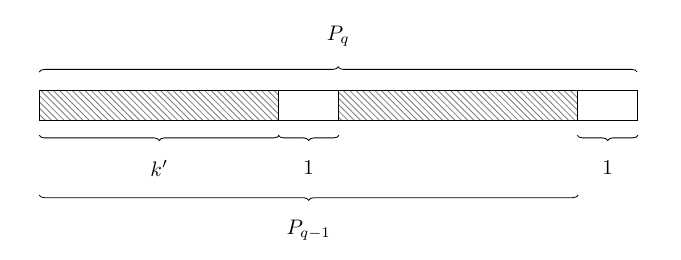
为什么P[k'+1]=P[q]就能说明P_{k'+1}就是P_q的最长公共前后缀呢?因为首先我们找到了P_{q-1},也就是P_q去掉最后一个字符得到的字符串的公共前后缀P_{k'}
图中是q=|P|的情况,很明显在P_{q-1}中,如果k'是P_{q-1}的公共前后缀并且P[k'+1]=P[q],则P_{k'+1}一定是P的公共前后缀,这点对于任意p\leqslant |P|都成立
我们一直往后倒着递减k'到0的位置,如果在这之前都没有任何一个合适的k',那么此时最长公共前后缀长度就是k'=0。而计算每上一个k'都有一个特殊的技巧,也就是k'=\pi[k](该算法的正确性将会在下文中证明),我们只需要不停的让k'=\pi[k],k=k',然后判断每一个k直到k=0为止,这就是函数的第6-7行所做的,它不停的递减k,并判断递减后的k是否满足P[k+1]。接着,如果找到了一个符合条件的k,或者一直迭代下去让k最终为0,则跳出循环,然后判断P[k+1]=P[q],这点是上文提到过的,如果符合那么就让k=k+1(从上图中可以轻松看到P_q的最长公共前后缀长度为k'+1),再循环的结束为止,将k储存在\pi[q]中,代表“P_q位置的最长公共前后缀长度为k”。
前缀函数的正确性证明
定义1:前后缀关系的传递性
对于字符串x, y和z,如果x\sqsupset y且y\sqsupset z,则x\sqsupset z,也就是说,后缀关系是传递的
对于字符串x, y和z,如果x\sqsubset y且y\sqsubset z,则x\sqsubset z,也就是说,前缀关系是传递的
定义2:后缀重叠引理
对于字符串x, y和z,如果x\sqsupset z且y\sqsupset z,则
- 有|x|\gt |y|\implies y\sqsupset x
- 有|x|\lt |y|\implies x\sqsupset y
- 有|x| = |y|\implies x = y
引理1:前缀函数迭代引理
令P是长度为m的模式串,\pi是P的前缀函数,也即\pi=max({\lbrace k:k\lt m且P_k\sqsupset P_m\rbrace}),对于q=1,2,...,m,设:
\pi^\ast[q]&=\lbrace \pi[q], \pi[\pi[q]], \pi[\pi[\pi[q]]]...\rbrace\\
&=\lbrace \pi[q], \pi^{(2)}[q], \pi^{(3)}[q], ...,\pi^{(t)}[q]\rbrace\\
\mathcal{S}&=\lbrace k:k\lt q且P_k\sqsupset P_q\rbrace
\end{aligned}
有
\pi^\ast[q]=\mathcal{S}
\end{align}
证明
这一条就是对于上文中k'=\pi[k],k=k'步骤的正确性证明,我们要证明这样得出的k'都可以令P_{k'}\sqsupset P_q,也就是这个迭代步骤中生成的所有k构成了P_q的所有公共前后缀的长度的集合。首先我们证明\pi^\ast[q]\sube\mathcal{S},令u=1且k_1=\pi^{(u)}[q]=\pi[q](由定义):
- 令u=1,则k_1=\pi^{(1)}[q]=\pi[q],由\pi的定义可以知道i一定属于\mathcal{S},即P_{k_1}\sqsupset P_q,并且k_1\lt q(别忘了看\pi的定义)
- 令u=2,有k_2=\pi^{(2)}[q]=\pi[\pi[q]]=\pi[k_1],观察到由\pi的定义可知P_{k_2}\sqsupset P_{k_1}\implies P_{k_2}\sqsupset P_q(由定义1),并且k_2\lt k_1\lt q\implies k_2\lt q。
由\lt的传递性和定义1中给出的\sqsupset的传递性归纳可得,对于任意的k\in\pi^\ast[q],
都满足
这意味着k\in\pi^\ast[q]\implies k\in\mathcal{S},也即
\pi^\ast[q]\sube\mathcal{S}
\end{align}
接下来证明\mathcal{S}\sube\pi^\ast[q],我们将会使用反证法证明两个集合的差是空集。首先,假设\mathcal{S}'=\mathcal{S}-\pi^\ast[q]\neq\phi,令j=max(\mathcal{S'}),我们知道max(\mathcal{S})=\pi[q](依旧是由\pi函数的定义直接给出了),也就是说必然有j\lt \pi[q]。因此,令j'\leqslant \pi[q]是\pi^\ast[q]中大于j的最小值(\mathcal{S}'中\pi[q]被删掉了,因此j才是\mathcal{S}'的最大值,这也是必然的,还是看定义,max(\mathcal{S})本身一定属于\mathcal{S},而max(\mathcal{S})=\pi[q],因此\pi[q]一定会在\mathcal{S}-\pi^\ast[q]时被删掉,这意味着\pi[q]一定不属于\mathcal{S}'),因为j和j'都属于\mathcal{S},因此可以知道P_j\sqsupset P_q并且P_{j'}\sqsupset P_q,又因为j\lt j',所以根据定义2可以知道P_j\sqsupset P_{j'},并且我们知道j是小于j'的最大值,所以必然有\pi[j']=j(因为j完美符合了\pi[j']的定义),又因为j'\in\pi^\ast[q],而从\pi^\ast[q]的定义可以知道\pi[j']\in\pi^\ast[q],即j\in\pi^\ast[q]。
为什么\pi[j']\in\pi^\ast[q]?因为定义,\pi^\ast[q]中的任意一个\pi^{(i)}[q]都等于\pi[\pi^{(i-1)}[q]]。因为j'\in\pi^\ast[q],所以可以令j'=\pi^{(i-1)}[q],则\pi^{(i)}[q]=\pi[j'],因为\pi^{(i)}[q]\in\pi^\ast[q],所以\pi[j']\in\pi^\ast[q]
然而我们在假设中强调了j\in\mathcal{S'},而\mathcal{S'}=\mathcal{S}-\pi^\ast[q],也就是说\forall_{s\in\mathcal{S'}}(s\notin\pi^\ast[q]),因此推出矛盾,证明了\mathcal{S}'必定是空集,这意味着
\mathcal{S}\sube\pi^\ast[q]
\end{align}
(2)和(3)一起,完成了对该引理的证明
引理2
设P是长度为m的模式串,\pi是P的前缀函数,则对于q=1,2,...,m,如果\pi[q]>0,有\pi[q]-1\in\pi^\ast[q-1],
证明
令r=\pi[q]>0,则从\pi的定义可以知道r<q并且P_r\sqsupset P_q,因此可以得知r-1<q-1并且P_{r-1}\sqsupset P_{q-1}(可以看上面的那张阴影图,如果x是y的后缀,那么这两个字符串各去掉末尾的一个字符之后得到的x'依然是y'的后缀),应用引理1可以知道,r-1\in\pi^\ast[q-1],也就是\pi[q]-1\in\pi^\ast[q-1],证明完毕
我们可以定义一个\pi^\ast[q-1]上的子集E_{q-1},该子集包含了所有属于\pi^\ast[q-1]并且可以拓展为P_q的k,也即
E_{q-1}&=\lbrace k\in\pi^\ast[q-1]: P[k+1]=P[q]\rbrace\\
&=\lbrace k: k\lt q-1\land P_k\sqsupset P_{q-1}\land P[k+1]=P[q]\rbrace\\
&=\lbrace k: k\lt q-1\land P_{k+1}\sqsupset P_q\rbrace
\end{align}
其中(5)实际上是把\pi^\ast[q-1]的定义展开,而(6)则是把(5)中的后两部分合并(为啥能合并?因为如果P_k是P_{q-1}的后缀,那么如果P[k+1]=P[q],就相当于说明P_k和P_{q-1}的后面一个字符也是相同的,因此算上这个字符之后的P_{k+1}依然是P_q的后缀),对于这个集合中的元素来说,只需要把自己递增1,让P_k变成P_{k+1},就可以变成P_q的一个公共前后缀,这个E_{q-1}的定义将会帮助我们证明算法第6-8行的正确性,它实际上描述的就是我们在开始正确性证明之前的那一段提到过的方法,“找到一个更小的k然后给这个k+1”
推论1
设P是长度为m的模式串,\pi是P的前缀函数,则对于q=1,2,...,m,有:
\pi[q]=
\begin{cases}
0&如果E_{q-1}=\phi\\
1+max(E_{q-1})&如果E_{q-1}\neq\phi
\end{cases}
\end{align}
首先,因为E_{q-1}的定义是“所有加上1之后就能让P_{k+1}\sqsupset P_q的k的集合”,所以如果E_{q-1}是空的,那么说明没有任何一个k能使得P_{k+1}\sqsupset P_q,此时根据定义,\pi[q]显然应当等于0。
如果E_{q-1}=\phi,则需要分两步证明,首先我们证明\pi[q]\leqslant 1+max(E_{q-1})。令r+1=\pi[p],则P_{r+1}\sqsupset P_q,因为r+1=\pi[q],所以r=\pi[q]-1,这蕴含了两点:1. r的值比\pi[q]小1,而\pi[q]一定小于q,因此r一定小于q-1。2. 根据引理2和之前提到的P_{r+1}\sqsupset P_q,可以得到r\in \pi^\ast[q-1]。综合这两点和之前提到的P_{r+1}=P_q以及E_{q-1}的定义可以得到r\in E_{q-1},因此r一定不大于E_{q-1}中的最大值,因此r\leqslant max(E_{q-1}),因为r=\pi[q]-1,所以\pi[q]-1\leqslant max(E_{q-1}),也就是:
\pi[q]\leqslant 1+max(E_{q-1})
\end{align}
接下来,我们证明\pi[q]\geqslant 1+max(E_{q-1})。由E_{q-1}的定义可以知道,对于任意一个k\in E_{q-1},都有P_{k+1}\sqsupset P_q并且k<q-1\implies k+1<q,因为\pi[q]规定了最大的k'使得P_{k'}\sqsupset P_q,因此k+1一定不大于k',也就是k+1一定不大于\pi[q](否则k不需要加1就有可能是P_q的后缀),又因为k\in E_{q-1},所以这蕴含着E_{q-1}中的任意一个k(包括最大的那个)加上1都不大于\pi[q],即:
\pi[q]\geqslant 1+max(E_{q-1})
\end{align}
(8)和(9)一起,完成了该推论的证明,这一个推论证明了算法第10行递增k的正确性
现在可以根据这三条结论来进行前缀函数的正确性证明了,在每次迭代开始前,k都等于\pi[q-1],也就是上一次迭代算出的\pi[q],在第一次迭代开始前,第3-4行保证了这点,第12行在每次迭代中都把\pi[q]设置为k,之后q递增1,保证了在下次循环开始前k=\pi[q-1],第6-8行计算\pi^\ast[q-1](因为此时的k在本次循环中还没有被更新,依然是\pi[q-1]的值),并算出最大的使得P[k+1]=P[q]的k的值,也就是E_{q-1}的最大值,这一点在引理2中说明,接着在9-11行根据(7),我们有足够的把握相信,如果k找到了,那么就应当让他递增1,如果k没有找到,则此时k的值一定是0,我们判断P[k+1]也就是P[1]和P[q]是否相等,如果相等则也给k递增1,不相等就继续让k的值等于0,代表在P_q没有任何公共前后缀,注意,如果k找到了,那么P[k+1]和P[q]一定相等,因为这是第6行while循环的跳出条件,第12行完成对\pi[q]的设置,并在第14行返回已经填充好的\pi表

Comments 1 条评论
草,是KMP,上学期数据结构学了。难怪听起来有点耳熟。